
Who Needs a “Human in the Loop” When AI Gives Itself Feedback
Directionally Correct Newsletter, The #1 People Analytics Substack

By: Ketaki Sodhi & Cole Napper
Subscribe to Directionally Correct newsletter to find more articles and access more insights on people analytics.
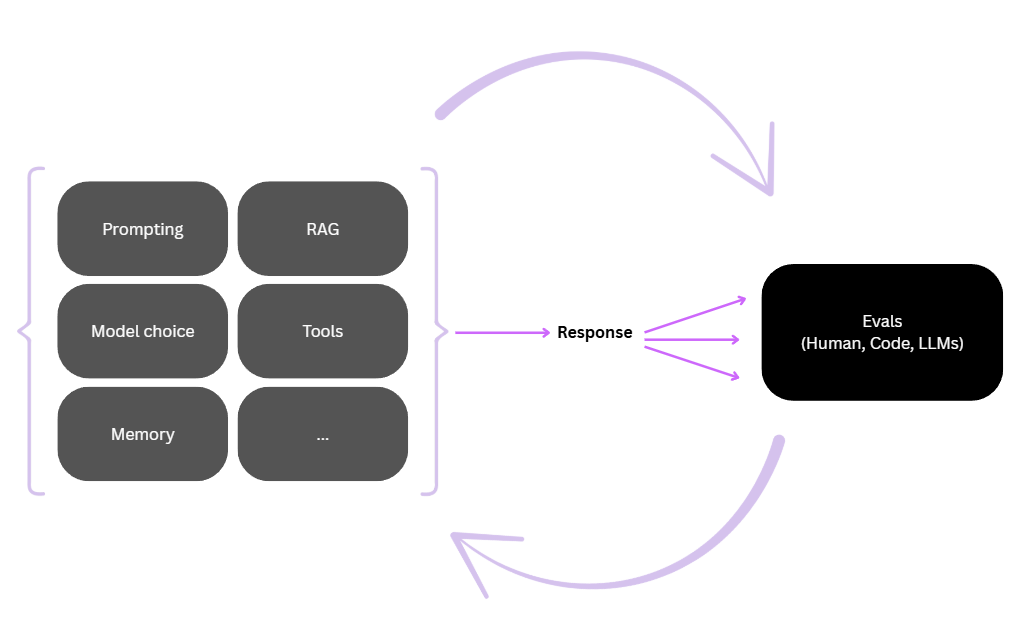
Introduction
While organizations rush…